
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
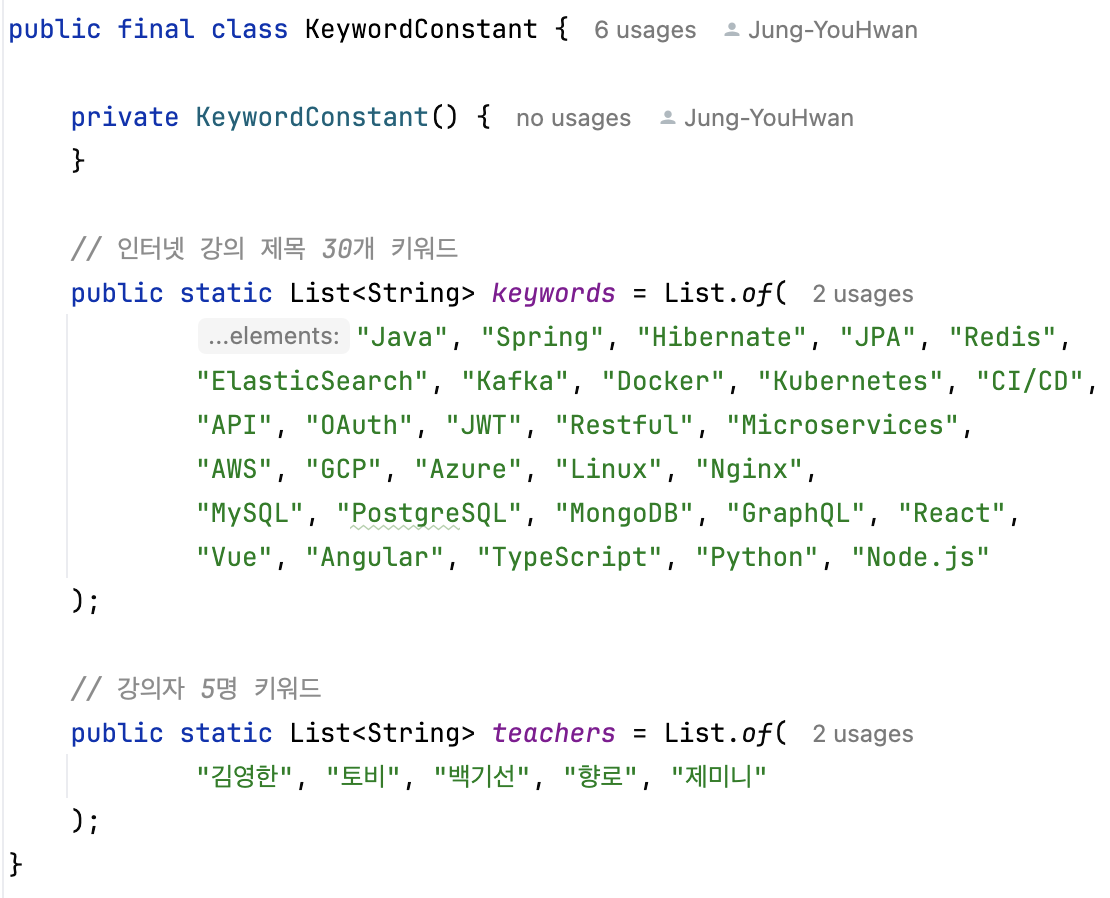
- java
- foreach
- Di
- jpa
- MySQL
- 동시성
- reflection
- 자바
- 스프링
- Synchronized
- Locking Read
- MVCC
- 가비지 컬렉터
- gc
- Atomic Type
- 동시성 문제
- 가비지 컬렉션
- 데이터 타입
- CAS
- 백엔드
- iterable
- Lock
- text
- db
- Varchar
- iterator
- Today
- Total
과정을 즐기자
필터링 검색 기능은 어떻게 구현되는 것일까? (feat. inverted index) 본문
여러 서비스를 이용하다보면 다음과 같은 필터링 기능을 볼 수 있습니다.

수많은 강의들이 있는데 Spring, MySQL, Node.js, React, SQL과 같은 키워드를 바탕으로 해당되는 강의들을 필터링해서
보여주는 기능입니다. 또 이러한 기술 검색 필터링 외에도 검색 키워드를 바탕으로 해당 키워드를 제목으로 포함한 강의를
보여주는 기능도 있을 수 있습니다.
검색 기능 구현을 위해서는 3가지 방법 정도가 생각납니다.
1. RDBMS의 like 키워드 사용
2. RDBMS의 Fulltext index 사용
3. Elasticsearch와 같은 검색 엔진 사용
기술적인 내용은 위와 같지만 이번 글에서는 이러한 기술은 조금 제쳐두고 조금 더 원리에 집중해서 어떻게 기능을 구현하면
좋을지 생각해보겠습니다.
📕 역 인덱스 (Inverted index)
조회 성능을 높이는 인덱스에 대해서는 많이 사용하고 있지만 역 인덱스 (inverted index)에 대해서는 조금 낯설 수도 있을 것 같습니다.
inverted index는 키워드를 통해 정보를 찾아내는 방식입니다. 인덱스와 역 인덱스의 기가 막힌 비유가 하나 있는데 인덱스는 책의
목차라고 생각하면 되고 역 인덱스는 책 뒷 부분의 찾아보기로 볼 수 있습니다.
역 인덱스는 기본적으로 key-value 형식이라고 볼 수 있습니다.
key 값에 특정 키워드를 넣고 value에 해당 문서에 대한 참조와 같은 내용을 넣을 수 있습니다.
📘 예제 만들어보기
예제를 하나 직접 만들어보며 역 인덱스에 대해 더 자세히 알아보겠습니다.
예제 요구 사항은 다음과 같습니다.
1. 인프런 강의 사이트와 같이 여러 키워드로 필터링을 할 수 있다.
2. 선택한 키워드를 제목으로 포함하는 강의 정보를 반환한다.
3. 키워드는 30개 정도로 하고 강의는 100만 건의 데이터를 넣어 결과를 비교해보자.
우선 100만 건의 데이터를 먼저 넣어보겠습니다.
하나의 강의에 1 ~ 3개의 키워드를 포함하도록 제목을 구성하였습니다.

역 인덱스를 사용하기 전에 "%like%" 연산자를 이용한 예제부터 살펴보겠습니다.


간단하게 Postman을 이용해 API 요청을 1번 날려보았습니다.
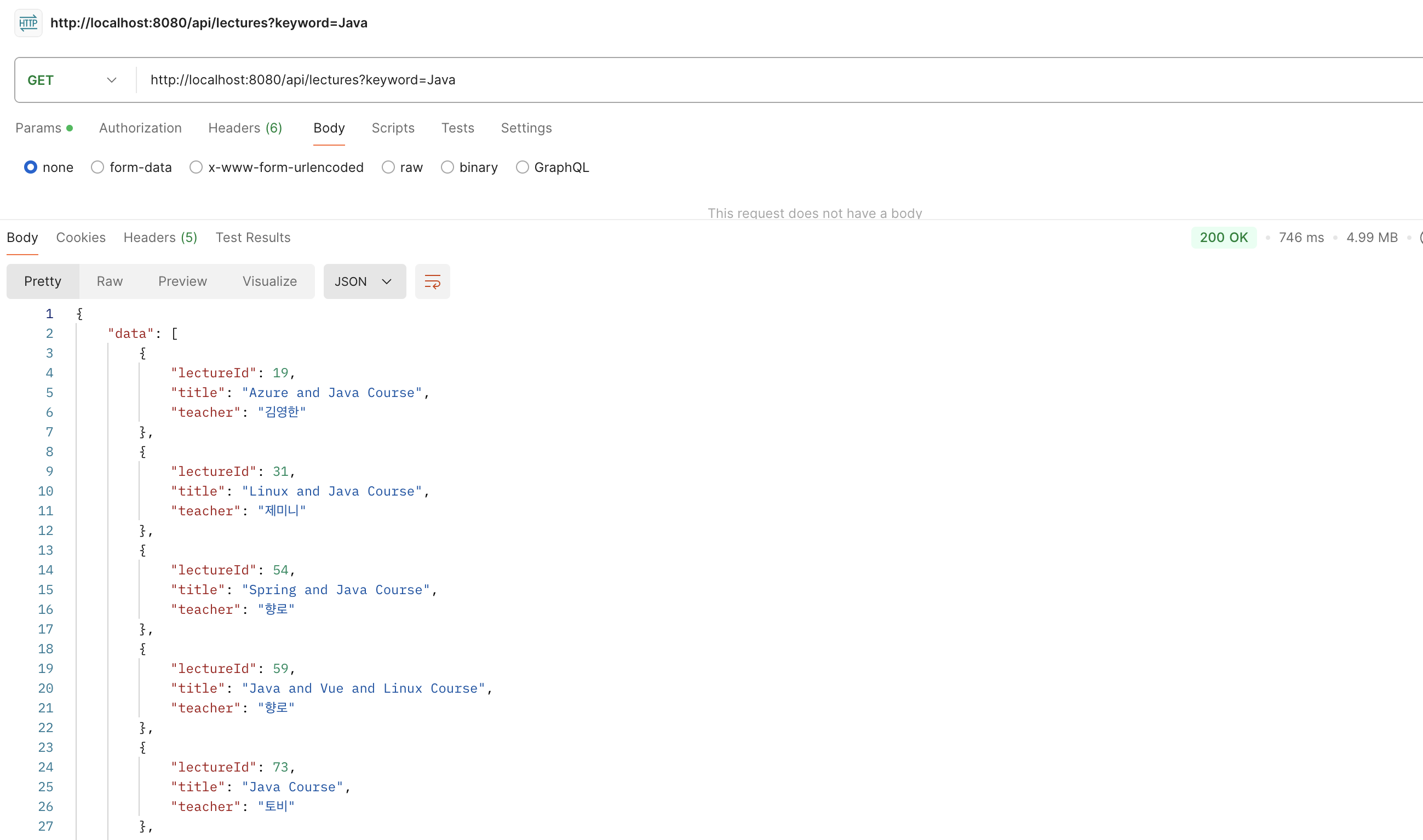
해당 요청의 응답 수는 100만 건중에서 66468 건 이었고 746ms가 걸렸습니다.
사실 이 쿼리는 title에 인덱스가 걸려있어도 인덱스를 활용하지 못하고 테이블 풀 스캔으로 실행됩니다.
약 6만 건의 데이터를 읽어오기 위해 테이블에 있는 100만 건의 데이터를 모두 읽어온다는 이야기입니다.
이제 역 인덱스를 활용한 코드를 작성해 보겠습니다.
LectureRepository 뿐만 아니라 key-value 형식의 Map인 keyworldInvertedIndex도 생성하였습니다.

원활한 예제 진행을 키워드 30개는 미리 key 값으로 넣어놓았습니다.

또 putKeyword() 라는 메소드를 통해 위에서 100만 건의 테스트 데이터를 저장할 때 lectureId, title, teacher 정보를
담는 LectureResponse 객체도 value 값으로 넣어주었습니다.

이제 해당 키워드 값이 들어오면 key 값에 맞는 value를 가져오기만 하면 됩니다!

다시 Postman을 이용해 이제 역 인덱스를 적용한 조회 API를 1번 날려보겠습니다.
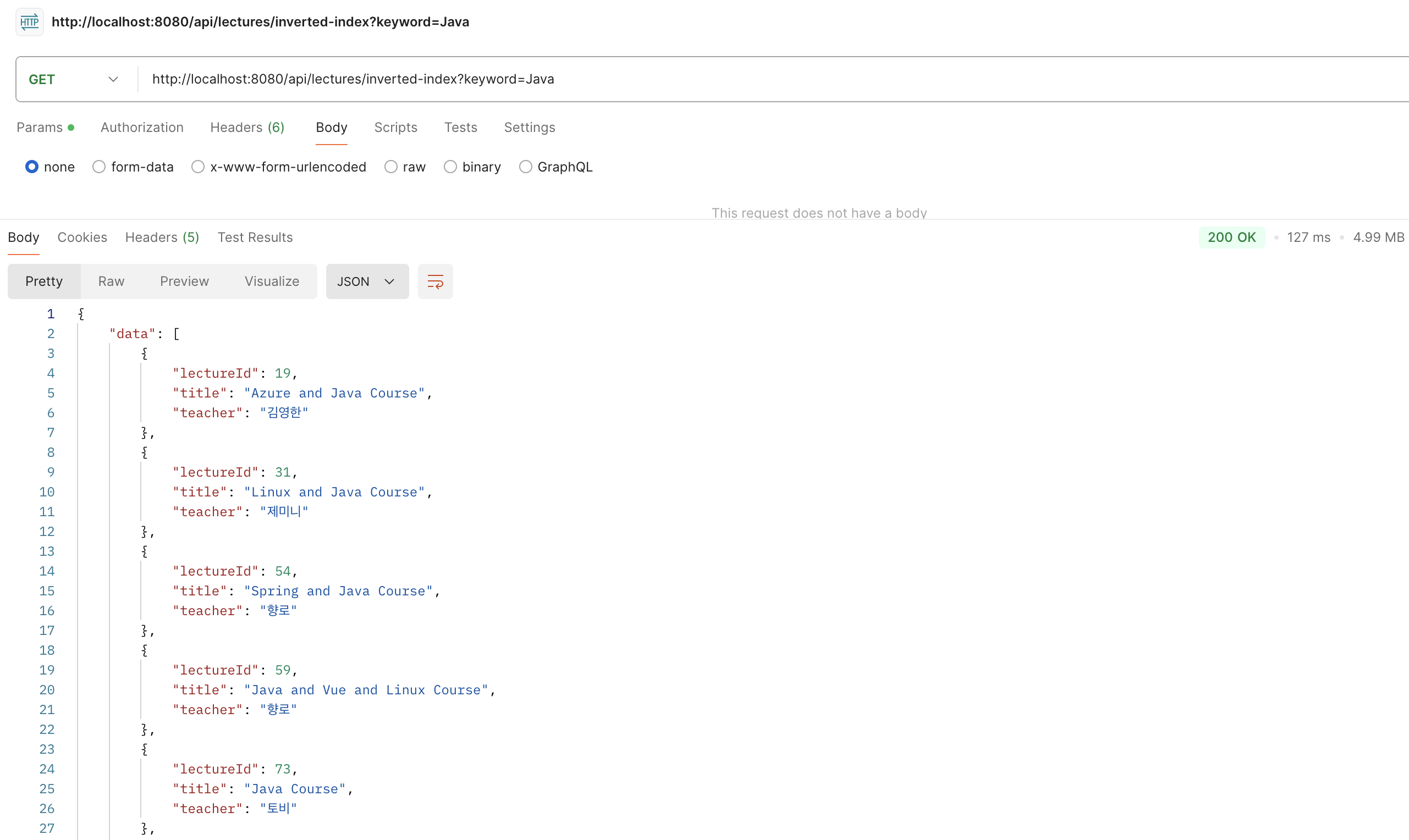
마찬가지로 100만 건의 데이터 중에서 66468 건의 데이터를 가져왔으며 조회에 걸린 시간은 127ms로 like 연산자를 사용했을 때보다
약 6배정도 빠른 성능을 확인할 수 있습니다.
📘 역 인덱스의 장단점
역 인덱스를 사용하면 키워드 기반으로 정보를 검색할 때 아주 빠르다는 장점이 있습니다.
하지만 역 인덱스도 인덱스와 마찬가지로 단점이 있습니다.
바로 조회 성능을 높이기 위해 삽입/수정/삭제의 성능은 어느정도 포기한다는 것입니다.
특히 역 인덱스는 위와 같이 몇 개의 정해진 키워드를 바탕으로 검색하는 것이 아니고 많은 키워드를 다뤄야 할 경우도 있습니다.
이 경우에는 문서를 띄어쓰기로 분리하고 대/소문자를 구분하며, 한글/영어를 구분하고, 불용어를 처리하고, 중복된 단어를 처리하는 등
여러 추가적인 많은 작업이 필요합니다.
📚 정리
이번 글에서는 역 인덱스를 통해 필터링 검색 기능이 어떻게 구현되었는 지 그 내부 방식을 알아보려고 하였습니다.
물론 위와 같은 작업을 애플리케이션 개발자가 일일이 하지 않고 Elasticsearch와 같은 검색엔진을 사용하는 경우가 훨씬 많을 것 같지만
그래도 알고 써야 더 잘 쓴다는 마음으로.. 정리해 보았습니다!
예제 코드
GitHub - 320Hwany/inverted-index: 역 인덱스 (inverted index) 방식 테스트
역 인덱스 (inverted index) 방식 테스트. Contribute to 320Hwany/inverted-index development by creating an account on GitHub.
github.com
'Database' 카테고리의 다른 글
| MVCC 만으로 팬텀 리드를 막을 수 있을까? (0) | 2024.10.27 |
|---|---|
| RDB는 정말 유연한 설계에 대응하는 것이 어려울까? (0) | 2024.03.24 |
| Lock을 이용한 트랜잭션 격리와 MVCC가 나온 이유 (0) | 2023.10.02 |
| RDB에서 동시성 문제는 왜 발생하며 어떻게 해결해야 하나? (0) | 2023.09.30 |
| 무작정 데이터 타입을 VARCHAR(16683)로 하면 안되는 이유 (0) | 2023.09.04 |


