
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 백엔드
- 동시성 문제
- 데이터 타입
- gc
- jpa
- iterable
- Synchronized
- reflection
- MVCC
- CAS
- Lock
- 가비지 컬렉터
- foreach
- Di
- 자바
- MySQL
- db
- iterator
- 스프링
- 동시성
- Varchar
- 가비지 컬렉션
- java
- Atomic Type
- Locking Read
- text
- Today
- Total
과정을 즐기자
JPA 양방향 매핑 사용하는게 맞을까? 본문
마주친 문제
예전에 했던 프로젝트(웹툰)에서 양방향 매핑을 사용하였습니다.
양방향 매핑을 사용하는 이유는 도메인 로직을 풀어낼 때 개발의 편의성이 크고
객체 지향적인 설계를 유지할 수 있기 때문입니다.
그래서 저도 양방향 매핑을 사용했지만 서로 순환 참조를 한다는 문제점이 있습니다.
이러한 점을 고려했을 때 어떠한 설계가 더 나은지 이야기 해보겠습니다.
양방향 매핑을 사용
먼저 양방향 매핑을 사용한 예시를 확인 해보겠습니다.
웹툰 서비스에서 작가(Author), 만화(Cartoon)가 OneToMany 양방향 매핑입니다.
Author
@Getter
@NoArgsConstructor(access = PROTECTED)
@Entity
public class Author extends BaseTimeEntity {
@Id
@GeneratedValue(strategy = IDENTITY)
@Column(name = "author_id")
private Long id;
private String nickname;
private String email;
private String password;
@OneToMany(mappedBy = "author", cascade = CascadeType.REMOVE)
private List<Cartoon> cartoonList = new ArrayList<>();
@Builder
protected Author(String nickname, String email, String password) {
this.nickname = nickname;
this.email = email;
this.password = password;
}
...
}
Cartoon
@Getter
@NoArgsConstructor(access = PROTECTED)
@Entity
public class Cartoon extends BaseTimeEntity {
@Id
@GeneratedValue(strategy = IDENTITY)
@Column(name = "cartoon_id")
private Long id;
private String title;
@ManyToOne(fetch = LAZY)
@JoinColumn(name = "author_id")
private Author author;
@Enumerated(EnumType.STRING)
private DayOfTheWeek dayOfTheWeek;
@Enumerated(EnumType.STRING)
private Progress progress;
@Enumerated(EnumType.STRING)
private Genre genre;
private double rating;
private long likes;
@Builder
protected Cartoon(String title, Author author, DayOfTheWeek dayOfTheWeek,
Progress progress, Genre genre, double rating, long likes) {
this.title = title;
this.author = author;
this.dayOfTheWeek = dayOfTheWeek;
this.progress = progress;
this.genre = genre;
this.rating = rating;
this.likes = likes;
}
...
}특정 닉네임을 검색했을 때 그 닉네임을 포함한 작가의 모든 만화를 검색하는 로직을 만들어보겠습니다.
AuthorService - findAllByNicknameContains
public List<AuthorCartoonResponse> findAllByNicknameContains(
AuthorSearchNickname authorSearchNickname) {
List<Author> authorList =
authorRepository.findAllByNicknameContains(authorSearchNickname);
return authorList.stream()
.map(AuthorCartoonResponse::getFromAuthor)
.collect(Collectors.toList());
}우선 authorRepository.findAllByNicknameContains() 메소드로 닉네임을 포함한 작가의 리스트를 가져온 후
지연 로딩으로 작가들의 모든 만화를 가져왔습니다.
만약 작가 리스트에 3명이 있다면 각각의 작가를 stream으로 돌려 지연 로딩으로 가져옵니다.
발생한 쿼리를 보겠습니다.
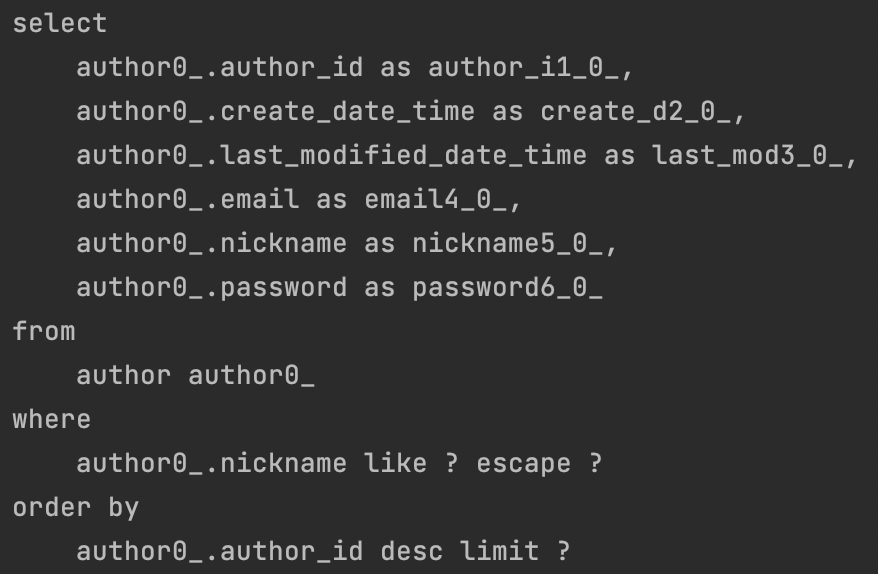
위는 작가 리스트를 가져오는 쿼리입니다.

위는 지연 로딩으로 연관관계를 가져오는 쿼리입니다.
조금 복잡해 보이는 로직이었지만 양방향 매핑의 편의성으로 다소 쉽게 해결하였습니다.
하지만 순환참조를 한다는 문제가 있습니다.
양방향 매핑을 사용하지 않기
양방향 매핑을 사용하지 않고 '특정 닉네임을 검색했을 때 그 닉네임을 포함한 작가의 모든 만화를 검색'
비즈니스 로직을 만들어 보겠습니다.
AuthorService - findAllByNicknameContains
public List<AuthorCartoonResponse> findAllByNicknameContains(
AuthorSearchNickname authorSearchNickname) {
List<Author> authors =
authorRepository.findAllByNicknameContains(authorSearchNickname);
return cartoonRepository.findAllByAuthors(authors);
}위와 같이 authorRepository 닉네임을 포함한 작가 리스트를 가져오고
cartoonRepository에서 작가 리스트를 파라미터로 받아 fetchJoin으로 다시 dto로 조회할 수 있습니다.
이렇게 양방향 매핑을 사용하지 않고도 충분히 해결할 수 있는 로직이었습니다.
정리
하지만 양방향 매핑을 사용할 때의 편의성은 분명히 존재합니다.
예를들면 작가를 삭제하면 만화를 삭제해야할 때 orphanRemoval, cascade 옵션으로 간단하게 할 수 있습니다.
이러한 경우에도 추가적인 로직을 더 작성하여 만화를 삭제하는 것이 더 좋은 방법이라고 생각하는 이유는
점점 더 규모가 커졌을 때 복잡도가 줄어들고 데이터의 접근 경로도 한방향으로 통일할 수 있기 때문입니다.
양방향 매핑의 편의성이 너무 확실해보이는 로직일 경우더라도 id를 간접적으로 참조하는 것이 나은 방법일 것 같습니다.
참고한 자료들
JPA 양방향 연관관계 관련하여 질문 드립니다. - 인프런 | 질문 & 답변
안녕하세요. 지식공유자님 강의 잘 듣고 있습니다. 순환참조 관련 설명을 해주시면서 외래키를 직접 들고 있는 편이 낫다고 하셨습니다. 실제로 최근에 최범균님의 JPA 강의를 들으면서 연관관
www.inflearn.com
양방향 매핑 - 인프런 | 질문 & 답변
안녕하세요~ 양방향 매핑을 사용하면 엔티티 간의 결합도를 높이기 때문에 가급적 단방향으로 만들면 좋다는 의견도 많은 것 같더라구요.심지어는 양방향 매핑을 만들어야 한다면 엔티티가 아
www.inflearn.com
'Spring Data' 카테고리의 다른 글
| 대량의 insert 쿼리 jdbc batch update를 사용하여 개선하기 (0) | 2024.04.23 |
|---|---|
| Spring Data JPA, Querydsl 사용하여 조회 기능 구현하기 (0) | 2023.03.17 |
| OSIV 설정을 False로 변경하기위한 리팩토링 과정 (0) | 2023.03.12 |
| JPA 지연 로딩 전략 사용시 Json 반환이 안될 때, N+1 문제 해결 (0) | 2023.01.29 |
| JPA 변경감지 적용이 안될 때 (0) | 2023.01.02 |



